April 13, 2026

A leadership team asks a question that cuts across multiple systems: operations, billing, supply chain, CRM, a partner feed. It should take minutes. Instead, the best analyst on the team disappears for three days — pulling data, waiting on access, and reconciling numbers across systems that don't agree. They come back with a spreadsheet, a caveat, and a number they're "mostly confident in."
This happens everywhere. In Consumer Packaged Goods, companies reconciling sell-through data across distributors. In insurance carriers stitching together claims, policy, and actuarial systems that were never designed to talk to each other. In healthcare organizations bridging multiple EMRs after an acquisition. In e-commerce platforms untangling operational costs across warehousing, logistics, and billing.
No AI analytics vendor wants to talk about the work required to connect the different sources, prepare the data, compute the answer and verify it.
Dozens of tools have shipped the same promise: connect your warehouse, ask a question in plain English, get an answer. Snowflake shipped Cortex. Databricks shipped Genie. Chat-with-data is becoming a platform feature.
These tools assume the hard work is already done. That someone has assembled the full picture from every relevant source, reconciled the conflicts, and verified that the result represents reality.
That assumption is wrong.
Enterprise data is permanently fragmented. Every SaaS tool creates a silo. Every acquisition brings a different schema. Every integration partner has their own format. The people who own the business context (operations, finance, supply chain, clinical teams) are stuck "prompting" people with the technology context across organizational and priority boundaries. And the number of sources per enterprise is growing, not shrinking.
The warehouse is the biggest source. It is not the single source of truth. Chat-with-data tools paper over that gap. They don't close it.
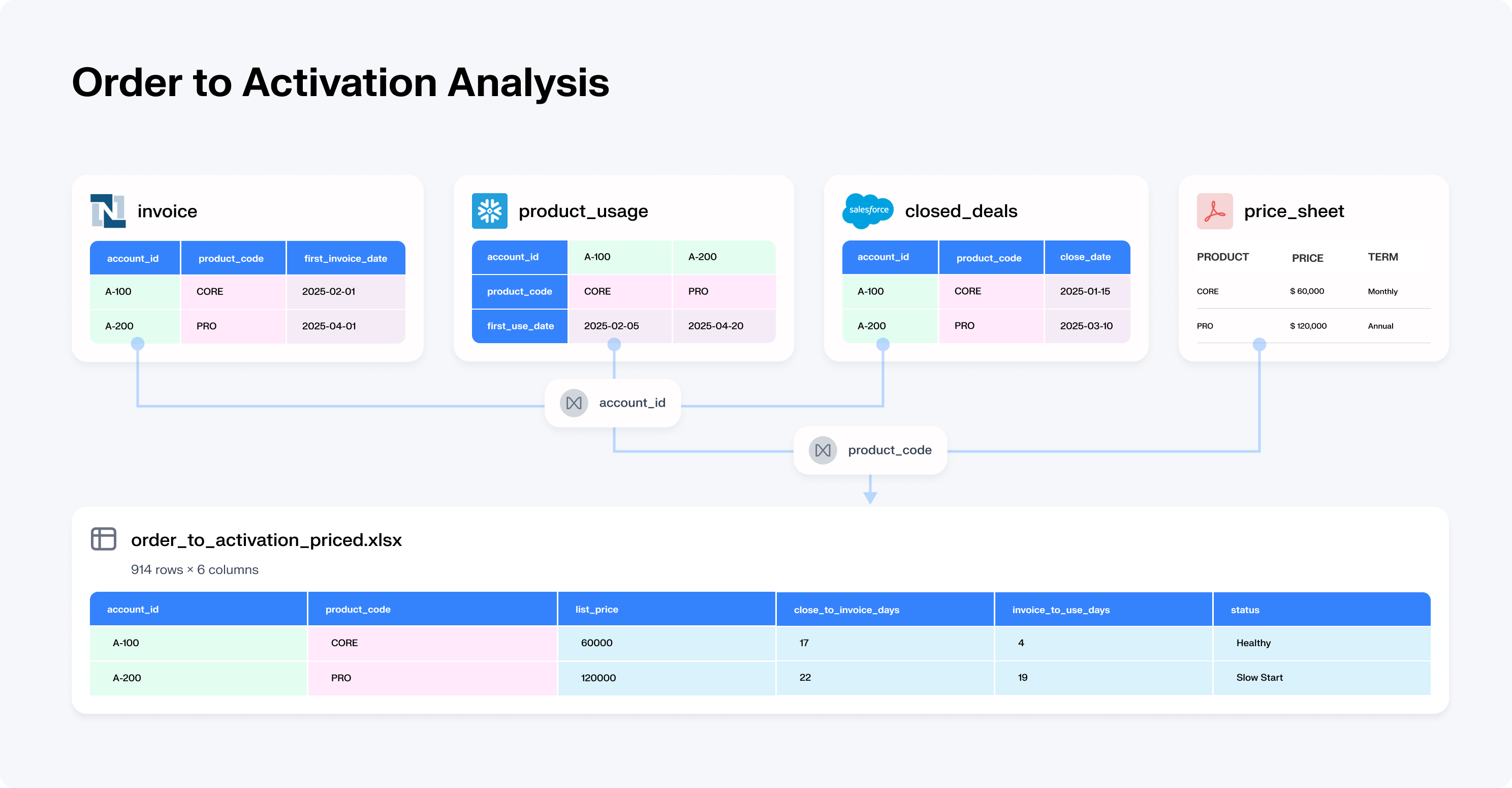
Most of the time, the data you need to answer the question doesn't exist in a form you can query. The real analytical work is everything that happens before the query: discovering which sources matter, assembling data from systems that weren't designed to connect, cleaning incompatible data types, reconciling conflicts when two systems define "revenue" or "customer" differently, and verifying that the final answer is internally consistent.
If your cloud data warehouse has tables with JSON field-types, it's not query-ready.
This is where 80% of analytical labor sits. It's the work chat-with-data tools skip entirely.
The answers that matter most live in the gaps between systems. An e-commerce company used aidnn to assemble data across their warehouse, billing system, and operational platform, sources that had never been joined, and discovered a 35% overpayment to a major vendor.
A logistics platform chose aidnn over Snowflake Cortex because it needed to reason across heterogeneous integrations spanning thousands of operators, not just query a single warehouse. No dashboard surfaced either insight. They required assembly and reconciliation across systems, not a query against one.
Every analyst who joins your company spends months learning the landscape. Which tables are trustworthy. What "active customer" or "revenue" actually means in your context. Which joins produce duplicates. How data from a partner feed lags your warehouse. This knowledge is invaluable, and fragile. When people leave, it leaves with them.
Every AI analytics tool on the market starts from zero every session. No memory. No context. No learning. At best, you bootstrap it with dbt and some table metadata, and pass the maintenance burden to engineering.
aidnn is different. From the first connection, it bootstraps organizational intelligence from your existing infrastructure: process knowledge, dbt models, metadata, data warehouse schema, existing pipeline code, dashboards. It doesn't start from zero. It starts from everything your organization has already codified.
Then it compounds. Every interaction teaches aidnn how your organization thinks about its data: which dimensions matter, which definitions are preferred, which edge cases your team cares about. When your team asks aidnn to re-plan, verify, redo, or rates an output, those judgments become organizational knowledge. When verification agents validate an analysis mathematically, the system captures which reconciliation approaches produce consistent results for your data. Proven patterns, not opinions.
And it unlearns. When business rules change, metric definitions evolve, or entity mappings shift, the system corrects itself based on how users steer it. Accumulated knowledge doesn't become accumulated liability.
After six months, use case by use case, aidnn has built institutional intelligence that a competitor would need six equivalent months to replicate. Not metadata you can export. Proven organizational knowledge that compounds with every interaction.
aidnn isn't an AI tool. It's a system built for the reality of enterprise data, one that continuously learns your data and your business context.
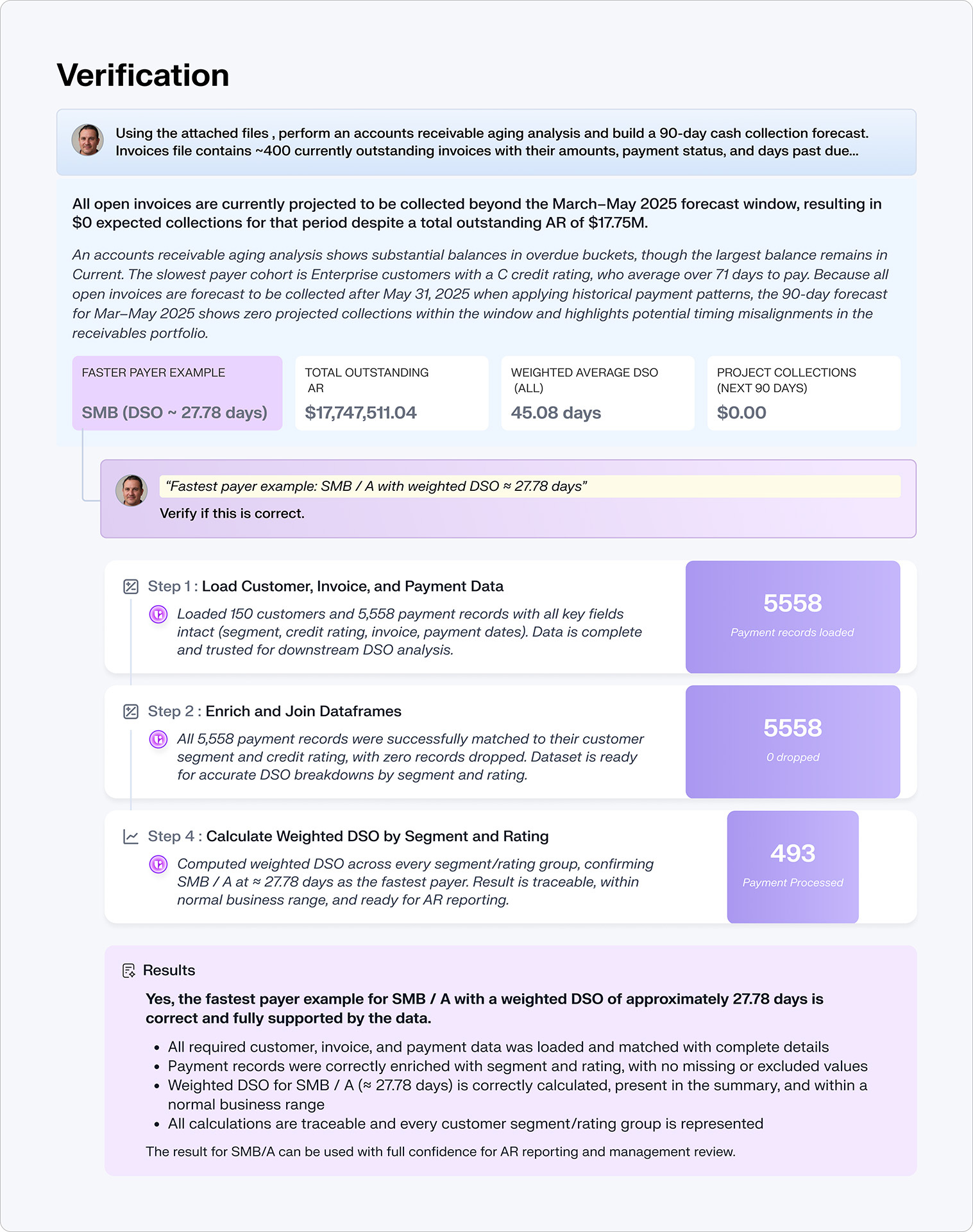
Here's the most dangerous thing about AI analytics tools: they don't verify their own work.
They generate code. If it runs, you get an answer. Whether that answer is correct (right source, right join logic, right interpretation) is your problem. You are the verification layer.
The failure mode isn't a crash. It's a clean chart with a precise number that happens to be wrong. Code that executed perfectly but answered the wrong question.
aidnn has a two-layer verification architecture no one has replicated:
Step Verification: independent agents verify every step in the analytical pipeline as it executes, catching errors before they propagate. Validated across 522 production sessions at 92.1% success rate (published research, arXiv, January 2026).
Deep Verification: after an analysis completes, formal verification agents generate mathematical constraints, invariants that must hold if the answer is correct, and test each one computationally. Revenue by region must sum to total revenue. Growth rates applied to the starting value must reproduce the ending value. Cross-source reconciliations must be bidirectionally consistent.
These aren't the same agents checking their own homework. They're independent agents with opposing incentives, a team of rivals, not a rubber stamp. This is what scales reliability from 50-60% per individual model to over 90% for the system.
Every answer comes with full evidence: what sources were used, how conflicts were resolved, what checks were run, what constraints were verified and why you should trust the number.
Chat-with-data is becoming a commodity. The next wave won't be defined by better natural language interfaces. It'll be defined by a simple question: can your tool verify its own work?
Your data is messy. It's going to stay fragmented. The question is whether your analytics platform was built for that reality, or whether it's still pretending the mess doesn't exist.